Data science competition entries

Image source: Vantage Circle
- Starting with the magnitude of the high turnover problem, the company is currently facing an overall turnover rate of 29.18%, and all of its ten departments are also facing high turnover rates ranging from 30.9% to 26.87%.
- To understand the most influential predictors of employee turnover, I built a CatBoost classification model with recall scores of 0.8446 on 5-fold cross validation and 0.8707 on the test data (with 20% of observations in the original dataset) by using the four most important features gauged with SHAP values, namely, the average working hours per month, employee satisfaction, review of employees by supervisors and the tenure of employees in number of years. Below is the SHAP value summary plot of all the predictors in the original dataset.
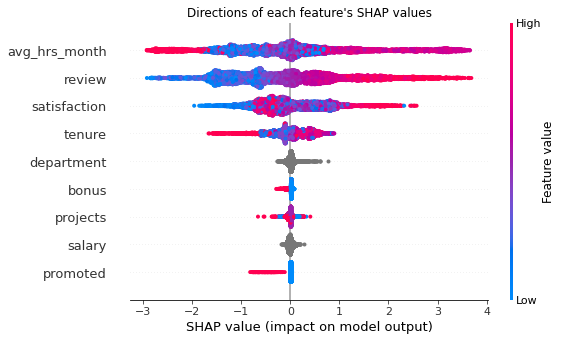
- It is found that in general, employees with higher monthly working hours are more likely to leave their current positions. In the case when employees have relatively low monthly working hours, those who are less satisfied with their work are also more likely to resign.
- Based on the above findings, I recommend that the company should provide better support or remuneration to employees who work longer hours each month so that they may be less likely to quit their jobs due to stress. Moreover, it will be important to know more about why some employees are not satisfied with their work in order to design strategies that can help them feel more satisfied.
- Lastly, since only 4 out of the 9 predictors in the dataset were significant for predicting employee turnover, I also suggested that more features such as employees’ relationship with their supervisors and seniority should be included in the future. This is to allow the testing of whether these features may also relate to employee turnover so that more tailored retention strategies can be devised.

Image source: Global Government Forum
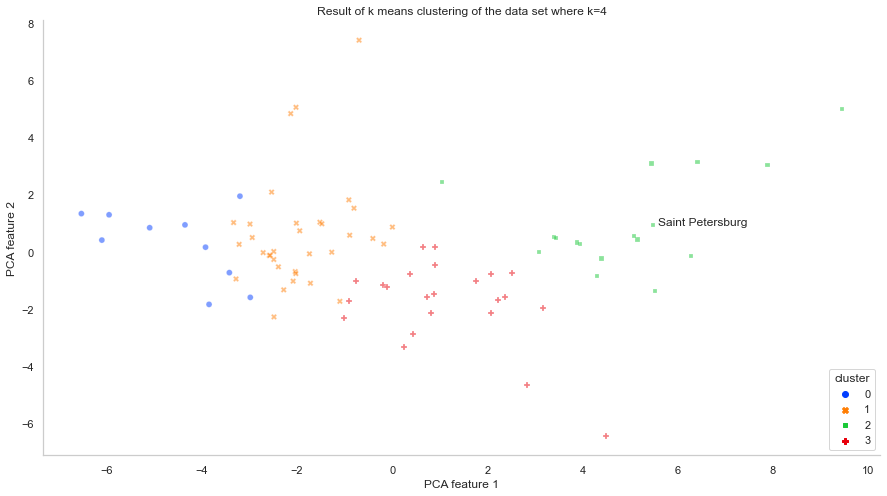
- To find out the 10 target regions in Russia for replicating a successful wine promotion campaign in Saint Petersburg, I first performed feature engineering on a time-series time of region-wise alcohol consumption pattern in Russia from 1998 to 2016 via using summary statistics to describe the regional consumption patterns during this period before using PCA to reduce the dimensionality of the dataset.
- Then I used k-means clustering with the four most important PCA features that altogether explain about 79% of the variance in the dataset. Apart from discovering the 10 target regions which share the most similar alcohol consumption patterns with Saint Petersburg, I also discovered that there are four regional clusters of alcohol consumption patterns in Russia mainly depending on the level of consumption. Accordingly, I suggested that future promotion campaigns can be tailored to each regional cluster for potentially better efficacy. Below is how regions in Russia are clustered according to their alcohol consumption patterns and where Saint Petersburg is located.
- Result: 3rd place